
Sort by Topics, Resources
Topics
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


Salto for
Salesforce
Articles
SHARE


Matt Grimwade
October 31, 2023
6
min read

Written in partnership with Ziipline. Ziipline is a multi-cloud Salesforce partner that puts innovation and business impact at the heart of everything we do. We partner with organisations of all sizes to build & deliver strategic Salesforce programmes designed to maximise your investment in Salesforce. You can find us at www.ziipline.com or on LinkedIn.
In part one of this article series, we explored how we can build configurable Salesforce solutions through the use of configuration data. By shifting our mindset and realising that configuration data is conceptually closer to metadata than data, we can start to leverage the metadata related benefits we already enjoy when building on Salesforce. But it’s not a silver bullet - these benefits bring their own challenges that we need to overcome to enable us to build faster and better:
Release Management
Visibility & Accountability
Versioning
Confidence in our Environments
Sandbox Seeding
If part one was the theory, you can think of this part two as the practical. We are going to deep dive into some of the tooling and approaches we can use to address the challenges outlined above.
We have tools like the Salesforce CLI that enable us to pull/push our metadata to/from a Salesforce org. We need to be able to do the same for our configuration data. There are several different tools available that can help us manage data within the context of a Salesforce org:
Each of these tools has their own use case. Right now we are going to deep dive into one of my favourite tools - SFDX Data Move Utility. Let's explore how we can use SFDMU to actually manage our configuration data and incorporate this into our devops processes.
SFDMU is an open-source plugin for the Salesforce CLI used for data migrations. It’s a developer focused CLI tool (although there is a GUI option, but I’ve not used it) that requires some hands-on JSON configuration to use. It’s great - I would describe it as the Salesforce data loader on steroids. Some of the key features include:
The above list doesn’t do the plugin justice though. Checkout the website or git repository to see how broad the feature set is. Although this plugin can be used for any data migration use case, it’s a great fit for our data as metadata scenario.
Just in the way you might use the Salesforce / SFDX CLI commands to push metadata from your local repository to an org, or vice versa, you can use SFDMU to do this for your configuration data - all through a single command. As it’s a command line tool you can also incorporate this into any automated CI/CD pipeline processes you may have set up.

Configuration of SFDMU takes place within a single JSON file named export.json. This is where being familiar with JSON structure will help.
This is a simple example snippet based on our fictional scenario. The core concept is that we define a query per object that we want to migrate using SFDMU. The plugin will automatically map the relationships between these objects. You may notice that field multiselect keywords, such as createable_true, are also supported - so we don’t have to maintain this file as new fields are added.
This is a really simple example. The full set of configuration options for the export.json file can be found here.
Running the tool is straightforward. There’s only a single ‘run’ command for both pushing and pulling data to/from an org.
Example command where we want to pull data from an org into CSV files into our local repository.
Example command where we want to push data from our local repository to an org.
The only difference is that we’ve flipped the source and target. The `csvfile` argument is a keyword that instructs the plugin to write to, or read from, CSV files in the local directory. The `sourceorg` and `targetorg` arguments are SF CLI aliases for my orgs.
Lets run the command to pull data from an org and see what we get:
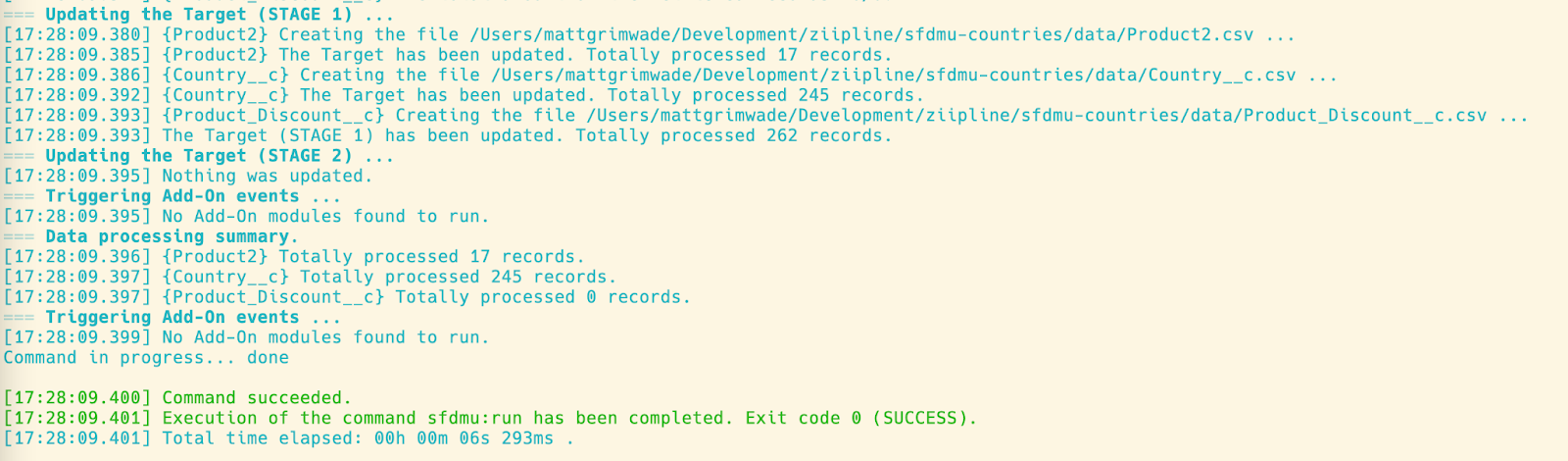
And finally, let's take a look at where the CSV files are stored within our local machine and how they appear in git.

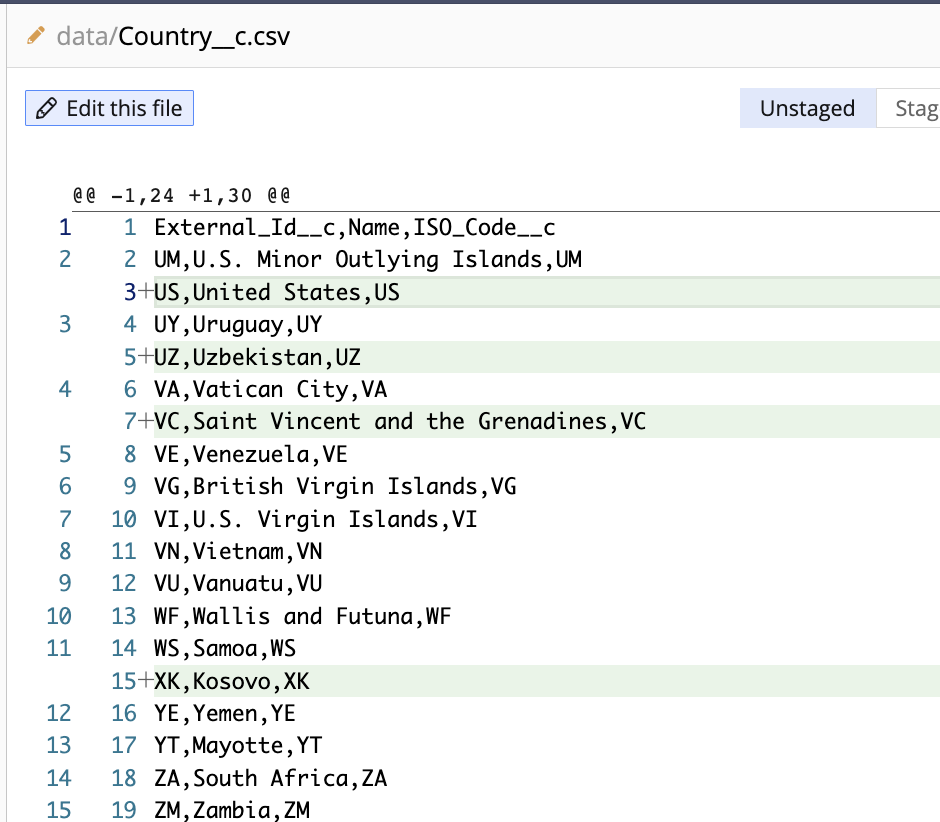
Just as when we change a single line of code, we can stage and commit only our specific changes to the data. As the products had already been added to git previously, only a change I made to a specific product record is picked up.
In this article we’ve explored through a simple scenario how we can use SFDMU to incorporate configuration data into our development process. However, SFDMU is just one tool we can use to manage this data. It’s a powerful and flexible CLI tool that is a worthy addition to a developer’s toolbox. If you made it this far I recommend you checkout the documentation.
In the end though, the choice of tool alone isn’t a magic bullet. What’s important is that we adopt the right mindset and start treating our configuration data more like our metadata. If we do this, we can deliver more quickly, build more configurable solutions and most importantly, make our lives easier.

WRITTEN BY OUR EXPERT
Matt Grimwade
Co-Founder at Ziipline
With over 10 years of consultancy experience delivering Salesforce solutions across a variety of clouds and industries, Matt enjoys delivering impactful change through technology. Coming from a developer & architect background, he is passionate about building cutting edge solutions on the Salesforce platform underpinned by modern devops tools & processes. Matt is currently co-founder of the Salesforce partner Ziipline that specialises in business & technology transformations through the Salesforce platform.
© Copyright Salto 2024 | Various trademarks held by their respective owners
Salto for
Salesforce
Salesforce
SHARE
Matt Grimwade
October 31, 2023
6
min read
Written in partnership with Ziipline. Ziipline is a multi-cloud Salesforce partner that puts innovation and business impact at the heart of everything we do. We partner with organisations of all sizes to build & deliver strategic Salesforce programmes designed to maximise your investment in Salesforce. You can find us at www.ziipline.com or on LinkedIn.
In part one of this article series, we explored how we can build configurable Salesforce solutions through the use of configuration data. By shifting our mindset and realising that configuration data is conceptually closer to metadata than data, we can start to leverage the metadata related benefits we already enjoy when building on Salesforce. But it’s not a silver bullet - these benefits bring their own challenges that we need to overcome to enable us to build faster and better:
Release Management
Visibility & Accountability
Versioning
Confidence in our Environments
Sandbox Seeding
If part one was the theory, you can think of this part two as the practical. We are going to deep dive into some of the tooling and approaches we can use to address the challenges outlined above.
We have tools like the Salesforce CLI that enable us to pull/push our metadata to/from a Salesforce org. We need to be able to do the same for our configuration data. There are several different tools available that can help us manage data within the context of a Salesforce org:
Each of these tools has their own use case. Right now we are going to deep dive into one of my favourite tools - SFDX Data Move Utility. Let's explore how we can use SFDMU to actually manage our configuration data and incorporate this into our devops processes.
SFDMU is an open-source plugin for the Salesforce CLI used for data migrations. It’s a developer focused CLI tool (although there is a GUI option, but I’ve not used it) that requires some hands-on JSON configuration to use. It’s great - I would describe it as the Salesforce data loader on steroids. Some of the key features include:
The above list doesn’t do the plugin justice though. Checkout the website or git repository to see how broad the feature set is. Although this plugin can be used for any data migration use case, it’s a great fit for our data as metadata scenario.
Just in the way you might use the Salesforce / SFDX CLI commands to push metadata from your local repository to an org, or vice versa, you can use SFDMU to do this for your configuration data - all through a single command. As it’s a command line tool you can also incorporate this into any automated CI/CD pipeline processes you may have set up.
Configuration of SFDMU takes place within a single JSON file named export.json. This is where being familiar with JSON structure will help.
This is a simple example snippet based on our fictional scenario. The core concept is that we define a query per object that we want to migrate using SFDMU. The plugin will automatically map the relationships between these objects. You may notice that field multiselect keywords, such as createable_true, are also supported - so we don’t have to maintain this file as new fields are added.
This is a really simple example. The full set of configuration options for the export.json file can be found here.
Running the tool is straightforward. There’s only a single ‘run’ command for both pushing and pulling data to/from an org.
Example command where we want to pull data from an org into CSV files into our local repository.
Example command where we want to push data from our local repository to an org.
The only difference is that we’ve flipped the source and target. The `csvfile` argument is a keyword that instructs the plugin to write to, or read from, CSV files in the local directory. The `sourceorg` and `targetorg` arguments are SF CLI aliases for my orgs.
Lets run the command to pull data from an org and see what we get:
And finally, let's take a look at where the CSV files are stored within our local machine and how they appear in git.
Just as when we change a single line of code, we can stage and commit only our specific changes to the data. As the products had already been added to git previously, only a change I made to a specific product record is picked up.
In this article we’ve explored through a simple scenario how we can use SFDMU to incorporate configuration data into our development process. However, SFDMU is just one tool we can use to manage this data. It’s a powerful and flexible CLI tool that is a worthy addition to a developer’s toolbox. If you made it this far I recommend you checkout the documentation.
In the end though, the choice of tool alone isn’t a magic bullet. What’s important is that we adopt the right mindset and start treating our configuration data more like our metadata. If we do this, we can deliver more quickly, build more configurable solutions and most importantly, make our lives easier.
© Copyright Salto 2024 | Various trademarks held by their respective owners


.png)












