
Sort by Topics, Resources
Applications
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


Salto for
Jira
Articles
SHARE


Knuckles
June 12, 2026
6
min read

Every conversation about Jira and AI is about your tickets. Rovo and Atlassian Intelligence will draft a description, summarize a thread, suggest a reply, search across your issues. It is all pointed at the end user filling in a ticket, and some of it is useful. But ask any Jira admin what actually eats their week, and it is not writing tickets. It is the configuration.
It is the 700 custom fields nobody has documented, half of them duplicates from a migration. It is the status someone renamed that quietly broke reporting in 300 other projects. It is the workflow scheme shared across teams you have never met, and the automation rule with no version history and no undo. It is the new hire who needs to understand an instance that lives only in one person's head. That work is unglamorous, it is constant, and it is exactly the kind of thing AI is good at. And almost no one is pointing AI at it.
This is the AI Jira admins actually want: not another helper for the person filling in a ticket, but an assistant for the person who has to keep the whole instance running. Here is what that looks like, and how to use it without putting your instance at risk.
The AI Atlassian puts in front of you is pointed at content: write this ticket, summarize that thread, find an issue. It lives where end users live. Admins in the community have been blunt about how little it does for them, and Rovo in particular gets a rough ride for not even reaching Atlassian's own configuration. Whether or not that is fair, it misses the point: none of it helps you manage the config.
The admin side has the opposite problem. There is no shortage of work AI could take off your plate, and no tool offering to do it: understanding what is in the instance, checking what a change will break before you make it, cleaning up the fields and schemes that have not done anything in years, editing hundreds of automations without hundreds of clicks. Admins are so starved for this that they build it by hand, exporting config to GitHub through the REST API and "treating it all as a development task." This is the gap, and it is where AI is most valuable.
Four kinds of admin work map almost perfectly onto what a capable AI agent does well.
None of this is for the person writing a ticket. None of it is what Rovo was built for. It is the boring, high-stakes work that keeps a Jira instance healthy, and it is finally something you can hand off.
Here is the catch. An AI agent is only as good as the context it has and the feedback it gets. Point it at the Jira admin UI through the API and it is working blind, one object at a time, with no way to see how anything connects. That is how you get confident, wrong answers, and it is exactly why admins warn each other to scope an agent's API token carefully so it cannot go off and break things.
At Salto, we represent your entire Jira configuration, including custom fields, screens, workflows, automations, filters, boards, and every permission, notification, and field-configuration scheme, as code, in a readable language we call NaCl. Every relationship between elements is explicit in the text.

This changes what the agent can do, for two reasons. First, context: the whole instance is in the one format AI understands best, with the connections spelled out, so when you ask what depends on a field, the agent follows the references instead of guessing. Second, a feedback loop: Salto runs Jira-aware validations on every proposed change and catches broken references and dependency problems immediately, so the agent corrects its own mistakes before you ever see the result.
Better context plus faster feedback is why the same agent that flails against the API does genuinely useful work against your configuration as code. It is also the version-controlled history and one-click undo that Jira never gave you for fields, workflows, and automations.
The number one objection admins raise about any tool that touches their config is trust. Would you let a third-party app, let alone an AI, read and change the instance your whole company plans its work in? It is the right instinct.
The safe pattern is to never give the agent the keys. It works on your Salto workspace, a versioned copy of your configuration, not on your live Jira, and it holds no Jira credentials. Every change it proposes is a readable diff that a human reviews and approves before anything is applied. Changes deploy through Salto's normal flow, with full history and one-click rollback. The agent can see everything and change nothing on its own.
Say you are finally cleaning up custom fields, and you find one named "AAA_test_custom_field." Obvious leftover test junk, right? Before you delete it, you ask the agent: what breaks if I delete this field? In seconds it traces a dependency the Jira UI never shows you on one screen. Despite the name, that field sits on 652 screens across the instance. Delete it and you strip a field from 652 screens at once, and you will not find out until the tickets start coming in.
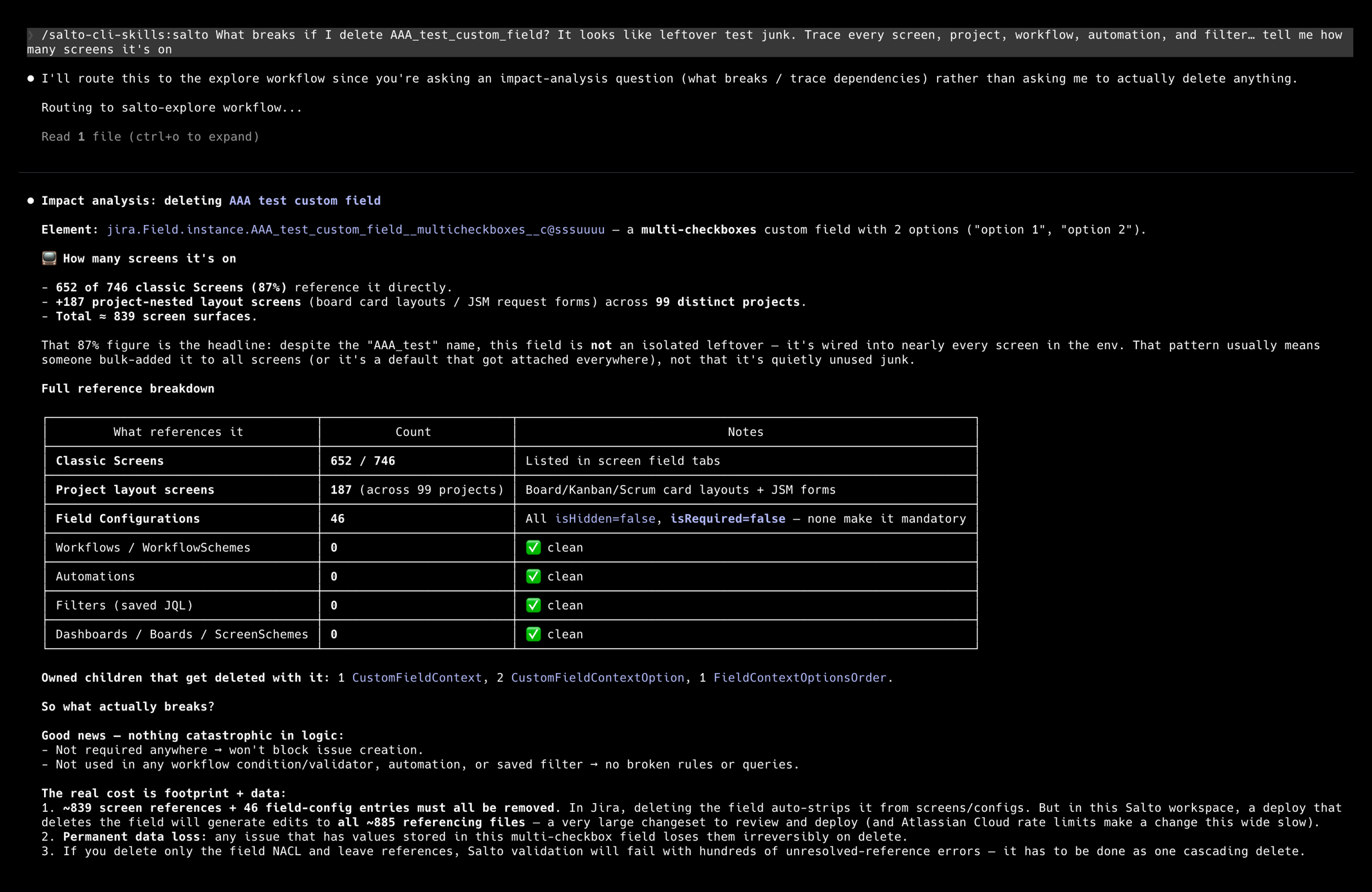
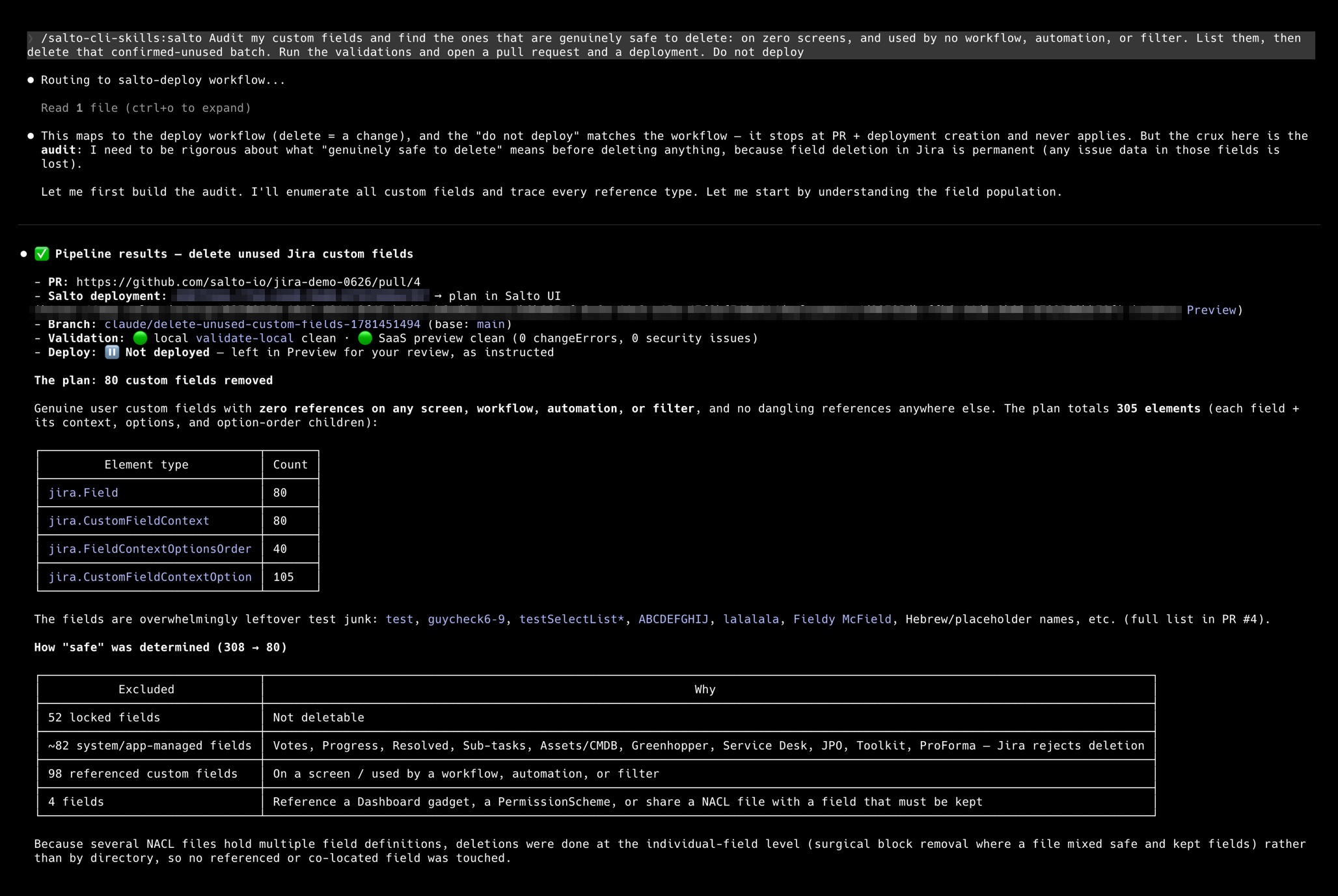
So the scary-named field is load-bearing. But the same audit surfaces the fields that genuinely are safe: a batch of custom fields that sit on zero screens and are used by no workflow, automation, or filter. Real orphans, the migration leftovers and abandoned experiments. You tell the agent to delete that confirmed-unused batch. It removes them, runs the validations, which would immediately flag any field that turns out to be referenced, and opens a pull request, all without touching your instance.
You review the exact change in Salto before anything happens. Each field to be removed shows up as a clean diff, the validations are green, and nothing reaches your instance until you click Deploy.
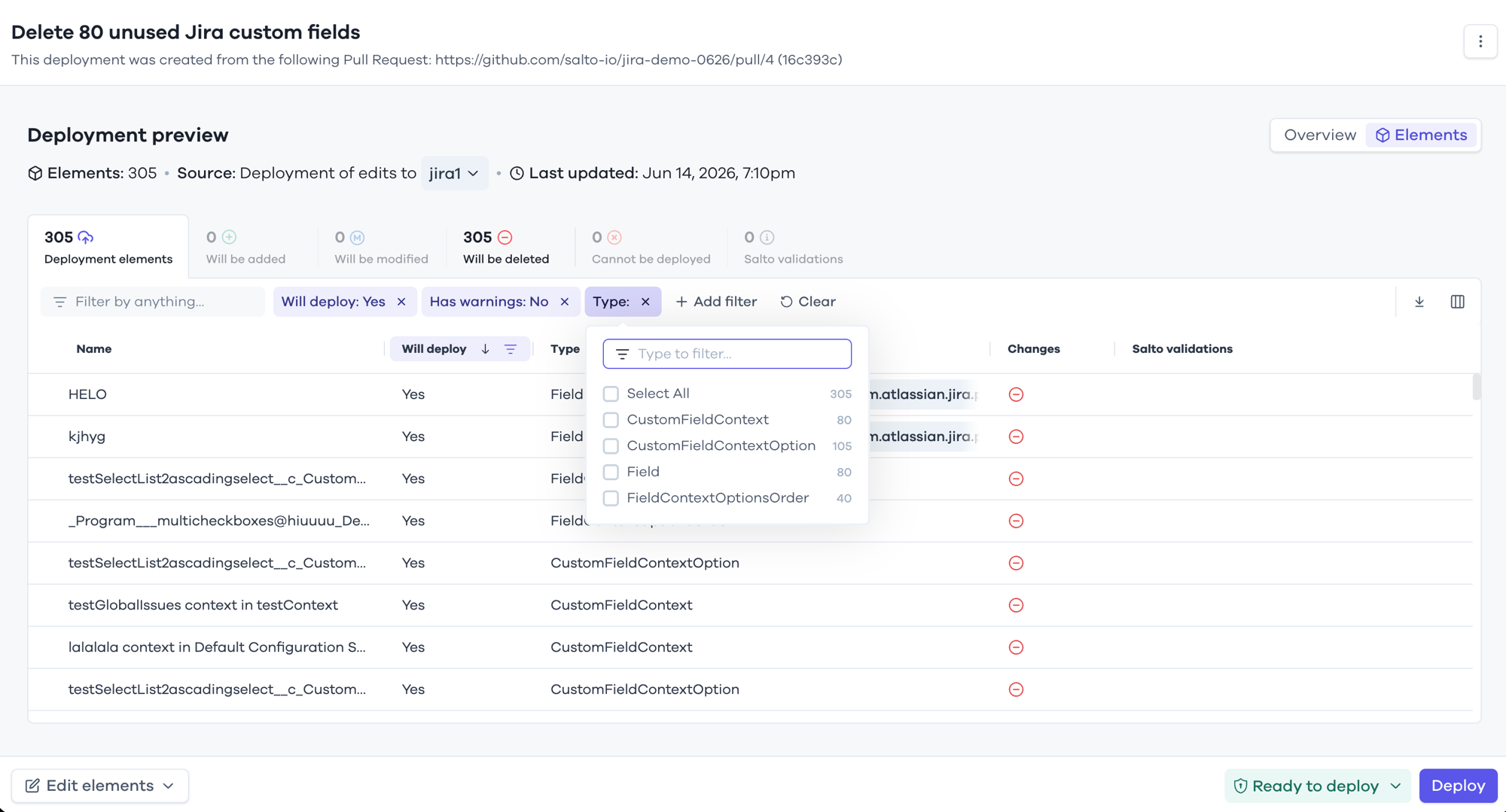
Every step is recorded, every step is reversible, and a human signs off on every change that reaches your instance.
Atlassian has spent its AI budget on the ticket, and that is fine, your teams write a lot of tickets. But the person keeping the instance running, the one who inherited 700 custom fields, a tangle of schemes, and automations with no undo, has been handed nothing. Configuration as code, an agent that understands it, validations that check every change, and a deploy flow that keeps you in control: that is what AI for the admin actually looks like. If you want to see it on your own instance, try Salto at salto.io.

WRITTEN BY OUR EXPERT
Knuckles
Chief Content Beaver
Knuckles is a curious Business Engineer who loves to explore all things business applications.
© Copyright Salto 2025 | Various trademarks held by their respective owners
Salto for
Jira
Jira
SHARE
Knuckles
June 12, 2026
6
min read
Every conversation about Jira and AI is about your tickets. Rovo and Atlassian Intelligence will draft a description, summarize a thread, suggest a reply, search across your issues. It is all pointed at the end user filling in a ticket, and some of it is useful. But ask any Jira admin what actually eats their week, and it is not writing tickets. It is the configuration.
It is the 700 custom fields nobody has documented, half of them duplicates from a migration. It is the status someone renamed that quietly broke reporting in 300 other projects. It is the workflow scheme shared across teams you have never met, and the automation rule with no version history and no undo. It is the new hire who needs to understand an instance that lives only in one person's head. That work is unglamorous, it is constant, and it is exactly the kind of thing AI is good at. And almost no one is pointing AI at it.
This is the AI Jira admins actually want: not another helper for the person filling in a ticket, but an assistant for the person who has to keep the whole instance running. Here is what that looks like, and how to use it without putting your instance at risk.
The AI Atlassian puts in front of you is pointed at content: write this ticket, summarize that thread, find an issue. It lives where end users live. Admins in the community have been blunt about how little it does for them, and Rovo in particular gets a rough ride for not even reaching Atlassian's own configuration. Whether or not that is fair, it misses the point: none of it helps you manage the config.
The admin side has the opposite problem. There is no shortage of work AI could take off your plate, and no tool offering to do it: understanding what is in the instance, checking what a change will break before you make it, cleaning up the fields and schemes that have not done anything in years, editing hundreds of automations without hundreds of clicks. Admins are so starved for this that they build it by hand, exporting config to GitHub through the REST API and "treating it all as a development task." This is the gap, and it is where AI is most valuable.
Four kinds of admin work map almost perfectly onto what a capable AI agent does well.
None of this is for the person writing a ticket. None of it is what Rovo was built for. It is the boring, high-stakes work that keeps a Jira instance healthy, and it is finally something you can hand off.
Here is the catch. An AI agent is only as good as the context it has and the feedback it gets. Point it at the Jira admin UI through the API and it is working blind, one object at a time, with no way to see how anything connects. That is how you get confident, wrong answers, and it is exactly why admins warn each other to scope an agent's API token carefully so it cannot go off and break things.
At Salto, we represent your entire Jira configuration, including custom fields, screens, workflows, automations, filters, boards, and every permission, notification, and field-configuration scheme, as code, in a readable language we call NaCl. Every relationship between elements is explicit in the text.
This changes what the agent can do, for two reasons. First, context: the whole instance is in the one format AI understands best, with the connections spelled out, so when you ask what depends on a field, the agent follows the references instead of guessing. Second, a feedback loop: Salto runs Jira-aware validations on every proposed change and catches broken references and dependency problems immediately, so the agent corrects its own mistakes before you ever see the result.
Better context plus faster feedback is why the same agent that flails against the API does genuinely useful work against your configuration as code. It is also the version-controlled history and one-click undo that Jira never gave you for fields, workflows, and automations.
The number one objection admins raise about any tool that touches their config is trust. Would you let a third-party app, let alone an AI, read and change the instance your whole company plans its work in? It is the right instinct.
The safe pattern is to never give the agent the keys. It works on your Salto workspace, a versioned copy of your configuration, not on your live Jira, and it holds no Jira credentials. Every change it proposes is a readable diff that a human reviews and approves before anything is applied. Changes deploy through Salto's normal flow, with full history and one-click rollback. The agent can see everything and change nothing on its own.
Say you are finally cleaning up custom fields, and you find one named "AAA_test_custom_field." Obvious leftover test junk, right? Before you delete it, you ask the agent: what breaks if I delete this field? In seconds it traces a dependency the Jira UI never shows you on one screen. Despite the name, that field sits on 652 screens across the instance. Delete it and you strip a field from 652 screens at once, and you will not find out until the tickets start coming in.
So the scary-named field is load-bearing. But the same audit surfaces the fields that genuinely are safe: a batch of custom fields that sit on zero screens and are used by no workflow, automation, or filter. Real orphans, the migration leftovers and abandoned experiments. You tell the agent to delete that confirmed-unused batch. It removes them, runs the validations, which would immediately flag any field that turns out to be referenced, and opens a pull request, all without touching your instance.
You review the exact change in Salto before anything happens. Each field to be removed shows up as a clean diff, the validations are green, and nothing reaches your instance until you click Deploy.
Every step is recorded, every step is reversible, and a human signs off on every change that reaches your instance.
Atlassian has spent its AI budget on the ticket, and that is fine, your teams write a lot of tickets. But the person keeping the instance running, the one who inherited 700 custom fields, a tangle of schemes, and automations with no undo, has been handed nothing. Configuration as code, an agent that understands it, validations that check every change, and a deploy flow that keeps you in control: that is what AI for the admin actually looks like. If you want to see it on your own instance, try Salto at salto.io.
© Copyright Salto 2025 | Various trademarks held by their respective owners











